Valimised on vähem kui kahe kuu kaugusel ning arusaadavalt hakkavad nii poliitikud kui valijad sellega seoses aina pingsamalt erakondade populaarsuse reitinguid jälgima. See on kahtlemata põnev ajaviide: meedia vahendusel saame reitingutabelite abil parteide kampaania-ponnistustele jooksvalt kaasa elada ja sarnaselt spordivõistlustele lõplikku võitjat ennustada. Seda tehes tuleb aga väga tähelepanelik olla.
Kõigepealt väärb alla joonimist erakondade populaarsuse küsitluse ning reitingute erinevus. Esimese puhul küsitakse vastajatelt nende eelistuse kohta (selle juurde mida täpselt küsitakse ning miks see oluline on tuleme hetke pärast detailsemalt tagasi) ning esitatakse kõigi vastuste jaotus. Reitingute puhul eemaldatakse vastustest tüüpiliselt kaks rühma: “ei oska öelda” ning “mitte ükski erakond” ning see võiks vähemalt teoreetiliselt anda jõudude vahekorra pildi, mis on võrreldav Riigikogu tänase koosseisuga.1
Erakondade reitinguid koostavad Eestis regulaarselt kõik kolm suurt uuringufirmat: Kantar/EMOR, Norstat ja Turu-Uuringute AS. Kõik nimetatud on hea reputatsiooniga, professionaalsed küsitluste korraldajad, nende küsitlused on esindusliku valimiga ning läbi viidud korrektse metoodikaga. Ometi on nende tulemused pahatihti päris oluliselt erinevad — mis muidugi võimaldab igal soovijal noppida kommenteerimiseks ning oma väidete kinnituseks sellise uuringu andmed, mis just talle kõige paremini sobivad.2
Nii näiteks on viimaste, augustikuu tulemuste alusel Reformierakonna reiting Norstati/ÜI hinnangul 30%, Emori ja Turu-uuringute andmete järgi 24%. See tähendab ca viiendiku võrra erinevat hinnangut suurima toetusega erakonna reitingule. Protsendipunktides on see erinevus 6%, mis on ligi neli korda suurem, kui Norstati (n=4000) valimi raporteeritud maksimaalne statistiline viga (±1,55%).
Et neid erinevusi selgitada, tuleb pöörata pilk metoodikale. Erinevus valimiste ja küsitluste vahel on selles, et kui esimesel puhul esitatakse küsimus kõigile valimisõiguslikele inimestele, siis teisel puhul ainult valimile. Valimi alusel tehtud tähelepanekute üldistamine kogu populatsioonile toob aga endaga paratamatult kaasa võimalikud vead ning ebatäpsused. Mõnesid neist on võimalik vältida (nt vead metoodika valikul, uuringu disainil või tulemuste esitamisel), mõnesid minimeerida (nt probleemid valimi representatiivsusega) ja kolmandaid hinnata (nt valimi suurusest tulenev maksimaalne statistiline viga).3
Nagu näha, on valimi koostamine ning metoodika valik siin võtmetähtsusega. Statistiline viga — mille väiksust uuringute läbiviijad uhkusega alla joonivad — on lihtsalt matemaatiline karakteristik, mis kirjeldab võimalikku variatiivsust valimi ning populatsiooni tulemuste vahel eeldusel, et valim esindab populatsiooni perfektselt. Näiteks kui me koostaks valimi ainult meestest, siis seda paisutades saaksime minimeerida statistilist viga, samas kui tulemused jääks endiselt ebatäpseks populatsiooni osas, millest veidi enam kui pooled on naised.
See viib meid otseteed küsitlusuuringute keskse probleemi juurde: kuidas tagada valimi representatiivsus? Lõpuks on ju populatsiooni võimalik liigendada tuhandel eri viisil — mitte ainult meesteks ja naisteks, eestlasteks ja venelasteks, noorteks ja vanadeks, vaid ka näiteks vasaku- ja paremakäelisteks või kassi- ja koera-inimesteks. Poliitilisi eelistusi puudutavate küsitluste puhul on kujunenud välja standard-pakett sotsiaal-demograafilisi tunnuseid, mille lõikes esinduslikkust silmas peetakse ja mis lisaks eelpool mainitud soo, rahvuse ja vanuse tunnustele hõlmab tavaliselt veel ka näiteks haridustaset, elukohta ja sissetulekut.
Kõigi nende rühmade proportsionaalse esindatuse saavutamine küsitluse valimis ei ole lihtne ülesanne. Näiteks on väga keeruline saada paneelidesse alg- ja põhiharidusega vastajaid (ja veel eriti, kui need on nooremad mehed). Osalt on siin tegemist sellega, et neid ongi suhteliselt vähem, teisalt aga ka sellega, et neid on tavalise (telefoni- või näost-näkku intervjuuga võrreldes ka odava) veebiküsitlusega keeruline tabada. Lahenduseks on siin kaalumine, mis korrigeerib valimis selle rühma vähesemate esindajate vastusteid kõrgema koefitsendiga. Sellel on aga hind tulemuse täpsuse osas.
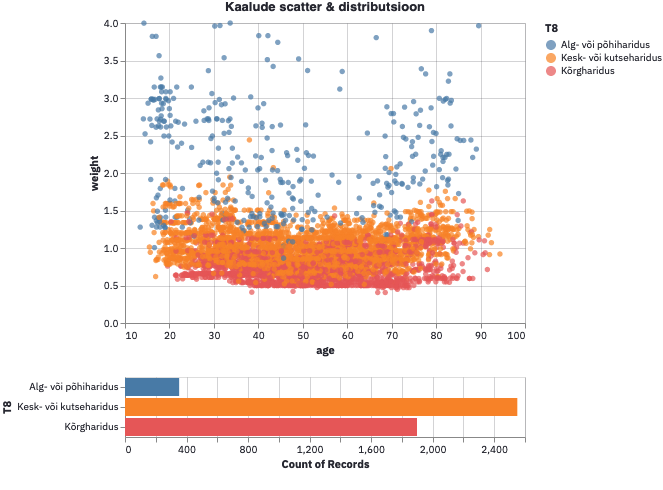
Seoses representatiivsusega on järgmiseks oluline märgata, et tüüpiliselt esitatakse küsimus vormis “Kui homme toimuks Riigikogu valimised, siis millisele erakonnale te oma hääle annaksite?”. See välistab vastajate hulgast nii 16-18-aastased kui mittekodanikud, kellel RK valimistel häält anda võimalik ei ole — küll aga saavad nad seda teha kohalikel valimistel. Arvestades, et Tallinnas jääb ainult kodanikke küsitledes arvestamata ligi viiendik valimisõigusega inimesi, kelle erakondlik eelistus on samas selgelt eristuv, on põhjust arvata, et selline valim näitab Keskerakonna toetust oluliselt madalamana sellest, milliseks see KOV valimiste päeval tõenäoliselt kujuneb. Samuti peab olema väga hoolikas küsimuse formuleerimisel selliselt, et see oleks vastajatele üheselt arusaadav, ei kallutaks ega raamistaks nende vastust — ning lõpuks ka nende vastuste interpreteerimisel, et neist ei tehtaks kaugemale ulatavaid järeldusi kui see, mida vastajad konkreetselt ütlesid.
Veel üheks oluliseks asjaks, millest reitinguid kommenteerides üllatavalt sageli mööda vaadatakse on tõsiasi, et kui näiteks n=1000 valimi statistiline viga on ca ±3%, siis selle valimi järgmiste tunnuste lõikes liigendamine suurendab viga väga kiirelt kordades. Nii on sisuliselt mõttetu teha üle-Eestiliselt representatiivse 1000-se valimi pealt mingeid prognoose Tallinna (või siis ammugi Viljandi või Narva) valimiste osas. Narva arvele langeks sellisest valimist tõenäoliselt ca 40 vastajat, mis annaks pelgalt statistiliseks veaks ±15,5%, rääkimata sellest, et sellisel puhul oleks valimi representatiivsuse tagamine üpris lootusetu.
Statistika on suurepärane tööriist, aga sellel on väga hea põhjus, miks seda ülikoolis aastaid õpitakse. Muide, Salgas pöörame oma andmete kvaliteedile ning metoodika korrektsusele äärmiselt suurt tähelepanu. Kogume neid väga hoolikalt, kontrollime igal sammul ja parandame jooksvalt. Nagu ütleb selle loo pealkirjaks olev kuulus, sageli Mark Twainile omistatud tsitaat, on statistikat hooletult või lihtsalt valesti kasutades oht sattuda väga valede järeldusteni — ja neid ka ise uskuma jääda.
1Tegelikult on ka siin veel väikseid, kuid olulisi lisadetaile, mida sedalaadi mehaaniline eemaldamine päris korrektselt arvesse ei võta (võtmesõnaks on siin d’Hondt), aga jäägu see praegu kõrvale.
2Huvi korral on kolme suure küsitlusfirma erakonna-reitingute põhjalik omavaheline võrdlus leitav siit.
3Siin on hea üldine üldevaade vigadest ja täpsusest statistikas.

